

Introduction
When it comes to working with high-dimentional data, searching for the nearest neighbor can be a computationally intensive task. For those unaware, high-dimensional data refers to datasets that contain a large number of features or attributes relative to the number of observations. For example, a sensor data from IoT devices or other sources can contain readings from multiple sensors, resulting in a high-dimensional dataset. Handling high-dimensional data can be challenging because of the "curse of dimensionality". This refers to the fact that as the number of dimensions increases, the number of data points required to accurately represent the data also grows exponentially.
One of the most efficient data structures for performing this type of search is a KDTree. In this blog post, I'll provide a technical overview of KDTree, explain why it is useful, and provide a step-by-step guide to implementing it in C++.
Why KDTree?
Although I briefly mentioned this in the Introduction, I would like to provide a more detailed explanation.
Consider a scenario where you have a large dataset with high-dimensional data points. Suppose you would like to find the nearest neighbors of a given query point. A straightforward approach would be to compute the distance between the query point and each data point in the dataset, and return the k-nearest neighbors. However, this approach quickly becomes computationally expensive as the size of the dataset and the dimensionality of the data increase.
KDTree provides an efficient solution to this problem by organizing the data points in a hierarchical tree structure. This structure allows for faster searches by eliminating the need to compare the query point with every single data point. Instead, the search is restricted to a small subset of the data points that are closer to the query point.
Technical Explanation
A KDTree is essentially a binary tree that is built using a set of high-dimensional data points. Each node in the tree represents a subspace of the high-dimensional space, and tree is built by recursively splitting the subspace into two regions along one of the dimensions.
At each level of the tree, one chooses a dimension to split the subspace. The dimension is selected based on the level of the tree, such that each level of the tree alternates between splitting the subspace along one of the dimensions. For example, if the root node splits the subspace along the x-axis, then the left child node will split the subspace along the y-axis, and the right child node will split the subspace along the z-axis.
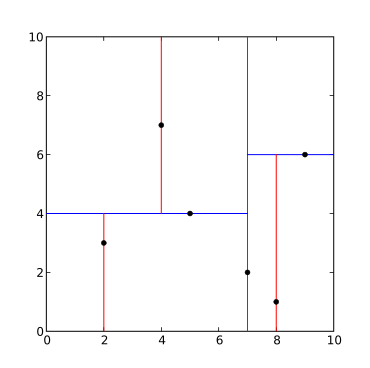
Figure 1 (src)
Important to note - the splitting of the subspace is done by finding the median value for the chosen dimension in the set of data points. The data is then partitioned into two subsets, one containing all points with value less than the median and one that contains all points with values greater than the median. And these subsets are used to create the left and right child nodes of the current nodes.
Once the tree is built, one can perform a nearest neighbor search by recursively traversing the tree. We start at the root node and move down the tree, choosing the left or right child node based on which subspace is closer to the query point. As we move down, we keep track of the best candidate nearest neighbor found so far. The best candidate is updated if necessary.
/*
* KDTree.cpp - Implementation of a k-dimensional tree.
*
* Author: Arth Patel
*
* Purpose: This file defines the functions necessary to build a k-dimensional tree and search for nearest neighbors.
*
* Side effects: None.
*/
#include <iostream>
#include <vector>
#include <algorithm>
#include <cmath>
// Define a struct to represent a point in k-dimensional space
struct Point {
std::vector coords; // Coordinates of the point
int id; // ID of the point
};
// Define a struct to represent a node in the KDTree
struct Node {
Point point; // Point associated with the node
Node* left; // Pointer to the left child
Node* right; // Pointer to the right child
};
// Define a function to calculate the distance between two points
double distance(Point p1, Point p2) {
double dist = 0.0;
for (int i = 0; i < p1.coords.size(); i++) {
dist += pow(p1.coords[i] - p2.coords[i], 2);
}
return sqrt(dist);
}
// Define a function to compare points based on a given dimension
bool comparePoints(const Point& p1, const Point& p2, int dim) {
return p1.coords[dim] < p2.coords[dim];
}
// Define a function to build the KDTree recursively
Node* buildKDTree(std::vector& points, int start, int end, int dim) {
if (start > end) {
return nullptr;
}
int mid = (start + end) / 2;
std::nth_element(points.begin() + start, points.begin() + mid, points.begin() + end + 1, [&](const Point& p1, const Point& p2) {
return comparePoints(p1, p2, dim);
});
Node* node = new Node;
node->point = points[mid];
node->left = buildKDTree(points, start, mid - 1, (dim + 1) % points[0].coords.size());
node->right = buildKDTree(points, mid + 1, end, (dim + 1) % points[0].coords.size());
return node;
}
// Define a function to search the KDTree for nearest neighbors
void searchKDTree(Node* node, Point query, std::vector& neighbors, int k) {
if (node == nullptr) {
return;
}
double dist = distance(node->point, query);
if (neighbors.size() < k || dist < distance(neighbors.back(), query)) {
if (neighbors.size() == k) {
neighbors.pop_back();
}
neighbors.push_back(node->point);
std::sort(neighbors.begin(), neighbors.end(), [&](const Point& p1, const Point& p2) {
return distance(p1, query) < distance(p2, query);
});
}
if (neighbors.size() < k || query.coords[node->point.coords.size() % node->point.coords.size()] - node->point.coords[node->point.coords.size() % node->point.coords.size()] <= neighbors.back().coords[node->point.coords.size() % node->point.coords.size()]) {
searchKDTree(node->left, query, neighbors, k);
}
if (neighbors.size() < k || node->point.coords[node->point.coords.size() % node->point.coords.size()] - query.coords[node->point.coords.size() % node->point.coords.size()] <= neighbors.back().coords[node->point.coords.size() % node->point.coords.size()]) {
searchKDTree(node->right, query, neighbors, k);
}
}
int main() {
// Create a vector of points
std::vector points = {
{{1.0, 2.0, 3.0}, 0},
{{4.0, 5.0, 6.0}, 1},
{{7.0, 8.0, 9.0}, 2},
{{2.0, 3.0, 1.0}, 3},
{{5.0, 6.0, 4.0}, 4},
{{8.0, 9.0, 7.0}, 5}
};
// Build the KDTree from the vector of points
Node* root = buildKDTree(points, 0, points.size() - 1, 0);
// Search for the k nearest neighbors of a query point
Point query = {{3.0, 4.0, 5.0}, -1};
int k = 2;
std::vector neighbors;
searchKDTree(root, query, neighbors, k);
// Print the IDs of the k nearest neighbors
std::cout << "The IDs of the " << k << " nearest neighbors of the query point are: ";
for (auto& neighbor : neighbors) {
std::cout << neighbor.id << " ";
}
std::cout << std::endl;
// Free the memory allocated for the KDTree
delete root;
return 0;
}

KDTree.cpp Program Output.
Github Repo
Check out my Github repository to clone the KDTree.cpp file.
github.com/arnpatel/KDTree

Use-cases
KDTree is useful in applications where we need to efficiently search for the nearest neighbors in high-dimensional space.
-
Search engines: We often need to search for documents or images that are similar to a query. We can represent each document or image with a high-dimensional feature vector, and use a KDTree to efficiently search.
-
Machine Learning: We often need to search for the k-nearest neighbors of a given point in high-dimensional space. We can search for k-nearest neighbors and perform classification or regression.
-
Datasases:: In database systems, we often need to search for similar records or find the closest neighbors to a given record.
An Example
Suppose we have a dataset of points in 2D space:
Point 0: (2, 3)
Point 1: (5, 4)
Point 2: (9, 6)
Point 3: (4, 7)
Point 4: (8, 1)
Point 5: (7, 2)
Point 6: (6, 8)
Point 7: (1, 10)
Point 8: (3, 9)
Point 9: (10, 5)
We can create a vector of Point structs to represent these points:
std::vector<Point> points = {
{{2, 3}, 0},
{{5, 4}, 1},
{{9, 6}, 2},
{{4, 7}, 3},
{{8, 1}, 4},
{{7, 2}, 5},
{{6, 8}, 6},
{{1, 10}, 7},
{{3, 9}, 8},
{{10, 5}, 9}
};
We can then build a KDTree using these points:
Node* root = buildKDTree(points, 0, points.size() - 1, 0);
Suppose we want to find the nearest neighbor of the query point (7, 6) in this dataset. We can create a Point struct to represent this query point:
Point query = {{7, 6}, -1};
We can then search the KDTree for the nearest neighbor using the following code:
std::vector<Point> neighbors;
int k = 1;
searchKDTree(root, query, neighbors, k);
After running this code, the neighbors vector will contain the nearest neighbor of the query point, which in this case is Point 2: (9, 6).